

Example of the Video Object Detection annotation tool where the annotator is assigned to label a car and it’s wheels.
AWS SageMaker GroundTruth Overview
Amazon SageMaker GroundTruth helps facilitate your data labeling needs for training machine learning models. It provides tools to create data labeling jobs as well as the annotation tools for labeling and reviewing data for image, text, video and LIDAR files.
For example, a self driving Tesla needs to be able to identify the road, other vehicles, people and obstacles to be able to drive safe and effectively. To do this, Tesla’s data science teams label hundreds of thousands of road scenes to feed Tesla’s machine learning model until the model performs consistently and accurately. This is an ongoing process as data scientists review how the model performs, gathers new data or new methods for creating an even stronger model. To the left (or above on mobile), is an example of the Video Object Detection annotation tool, where the annotator is assigned to label a car and it’s wheels.
SageMaker GroundTruth Product Vision
Define Why
PROBLEM
The team had bought many third party annotation tools to keep up with customer demand and, due to this, GroundTruth had ~20 custom product solutions for data labeling. There were many different ones due to task type, data type and other industry specific needs (i.e. Ontology linking within text named entity recognition for the medical industry). This made it very hard to manage, maintain and scale. Generative AI was also taking storm and the team needed to invest in data labeling tools for generative AI models to stay competitive. (Fortune business anticipates, “the global generative AI market size to grow from $43.87 billion in 2023 to $667.96 billion by 2030.”) New custom solutions were being requested by new customers and drag and drop WYSIWYG’s (no code, visual “What you see is what you get” experience) started to appear on the market to easily build custom data labeling tools by competitors.
SOLUTION
My vision was to create one data labeling tool for all data labeling needs regardless of task type, data type or industry. This tool would have three variants for the three distinct personas; Job creator, Annotator and Reviewer.
The design deliverable is a design system. Forward looking, the hope was that the team would leverage this design system to scale with generative AI to generate custom solutions for our customers. I was working with data science, user research, engineering and PM’s to discuss what would be needed to generate custom data labeling tools by feeding our design system in and outputting custom solutions that were not yet built. This, paired with the GroundTruth WYSIWYG tool that would predate it, would significantly reduce the amount of internal operations spent investing in one-off custom solutions for customers and we could reprioritize efforts to building net new assets and components and adding these to the design system.
MY ROLE
UX and Project Lead
KEY PERFORMANCE INDICATORS
Reduce internal operations spent on managing & maintaining portfolio of products by 15%.
Stop creating custom one-off solutions.
Increase customer adoption by providing generative AI, custom and scalable tools by 20%.

Forward looking: A mock up I made leveraging Generative AI for the Job creator to quickly output new, custom data labeling jobs. This mock was circulated and discussed among the team.




Research
MARKET RESEARCH
To clarify vision, I dove into market research where I:
Developed a unique brainstorming session where I created a FigJam board to outline each customer use case and included screenshots of existing solutions. I gathered a team of internal stakeholders and designers where we brainstormed potential opportunities to innovate on behalf of our customers. This helped illuminate relevant ideas for customers with the ultimate goal of potential added revenue.
Discussed needs, opportunity and ideas with 6 customers, all with a deal size between $3-10 million. Each discussion held as one-on-one moderated 60 minute interviews.
Looked and documented competitive tools on the market to understand where we could innovate, what we were missing and where we were strong.
Key insights
The team was focusing on creating custom solutions for customers rather than investing in a long term, scalable solution.
The team needed to start investing in Generative AI data labeling services to stay competitive.
PRODUCT RESEARCH
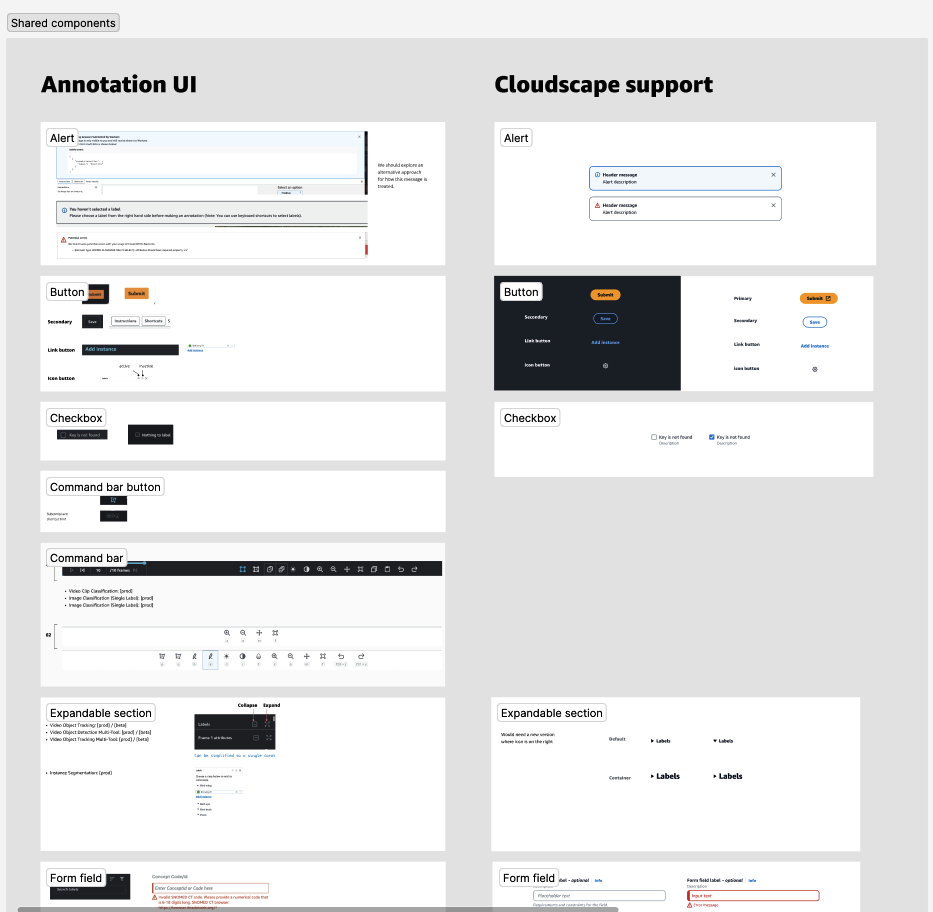
Looking at our disperse amount of solutions (see gallery to the left if on a desktop. Above on mobile), it became clear that there was an opportunity to consolidate and this was validated by engineering. The gallery to the right shows a few of the different solutions offered. You may be able to notice differences in the UI/UX. There was also two code bases which made it extremely cumbersome for engineering to keep up with demand.
Personas and user flow
PERSONAS
There are three personas within data labeling in SageMaker GroundTruth:
Job creator: The person who creates the task template. They are coming to GroundTruth console to create jobs and track progress of their data being labeled.
Annotator: The person or team of people that are in-house or third party contractors in charge of labeling data. Sometimes they will be specialized depending on the industry or problem being solved. They primarily work within the data labeling tool.
Reviewer: This is a high skilled quality assurance check of the annotators work. They will typically review a team of annotators work as it’s completed. They primarily work within the data labeling tool with additional functionality for sending feedback and rejecting work.
The key success metrics for the data labeling tool are time on task and accuracy. The team is constantly looking for ways to reduce the amount of time it takes for an annotator to output highly accurate data labels. With hundreds and thousands of data to be labeled, the faster and more efficient the team can label data, the more clients we can take on which has the potential of up to $20 million growth.
USER FLOW
A job creator builds the initial task template within the GroundTruth console then sends the job to the annotator. The annotator will spend time labeling the data based on the instructions the job creator set up. The reviewer will either send feedback back to the annotator or will complete the job and send the final labeled data back to the job creator.

A job creator creates the initial task template then kicks off the job to the annotator. The annotator will spend time labeling the data based on the instructions the job creator set up. The reviewer will either send feedback back to annotator or will complete the job and send the final labeled data back to the job creator.

Prioritization
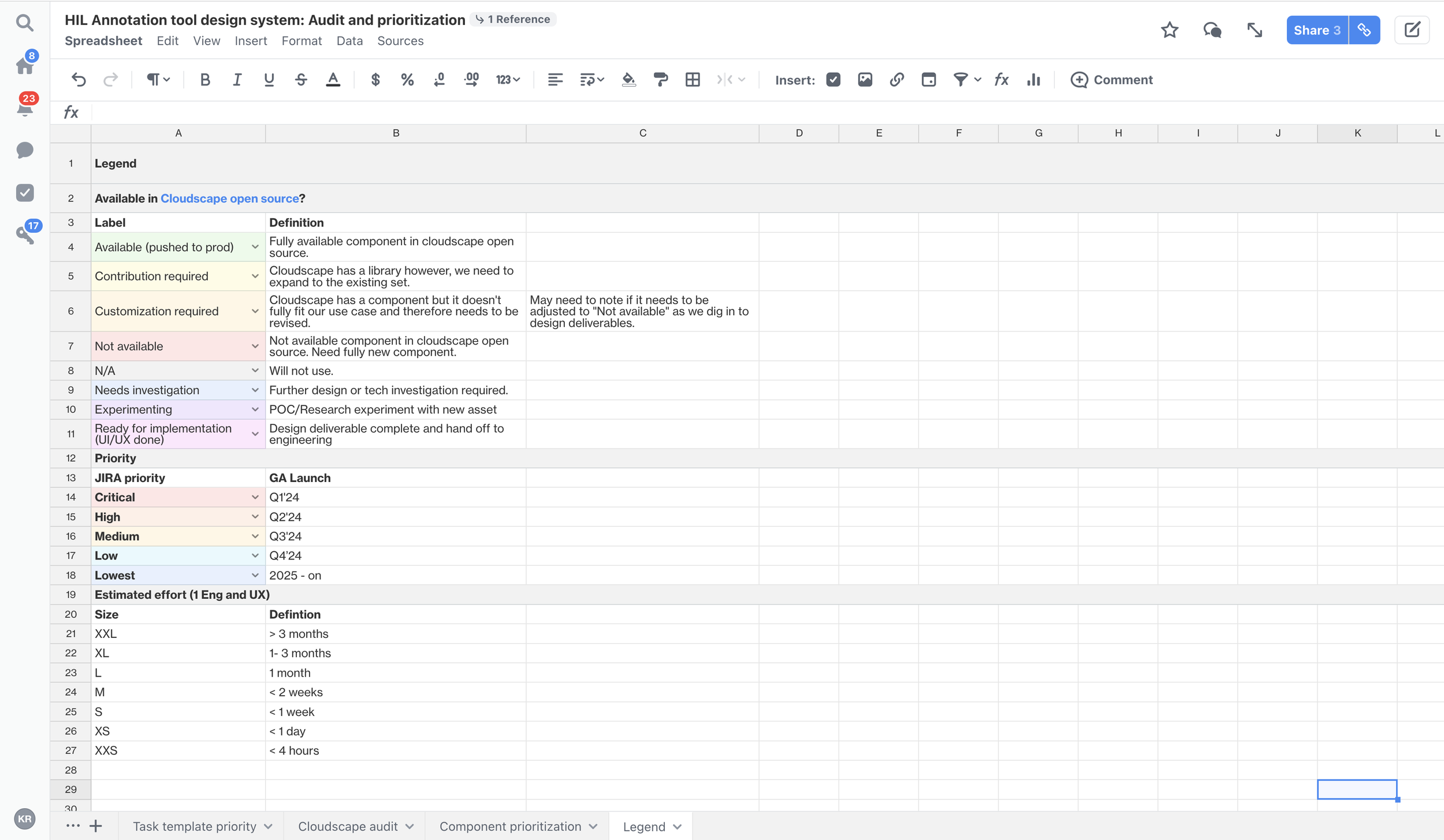
Blake Weber, a contractor and design system wizard on my team, did a component analysis across the GroundTruth’s portfolio of products. From this, I created an audit where I set the task template priority and the corresponding net new components that would need to be made as our first round of deliverables.
Generative AI task templates were prioritized due to the relevancy in the market. Also, GroundTruth did not have tools for these problems yet which made it an easy place to start building and consider scaling.
Test and iterate: High fidelity mocks
Generative AI had several product use cases:
Response classification
Text summarization and revision (grouped because it leverages the same UI/UX)
Q&A
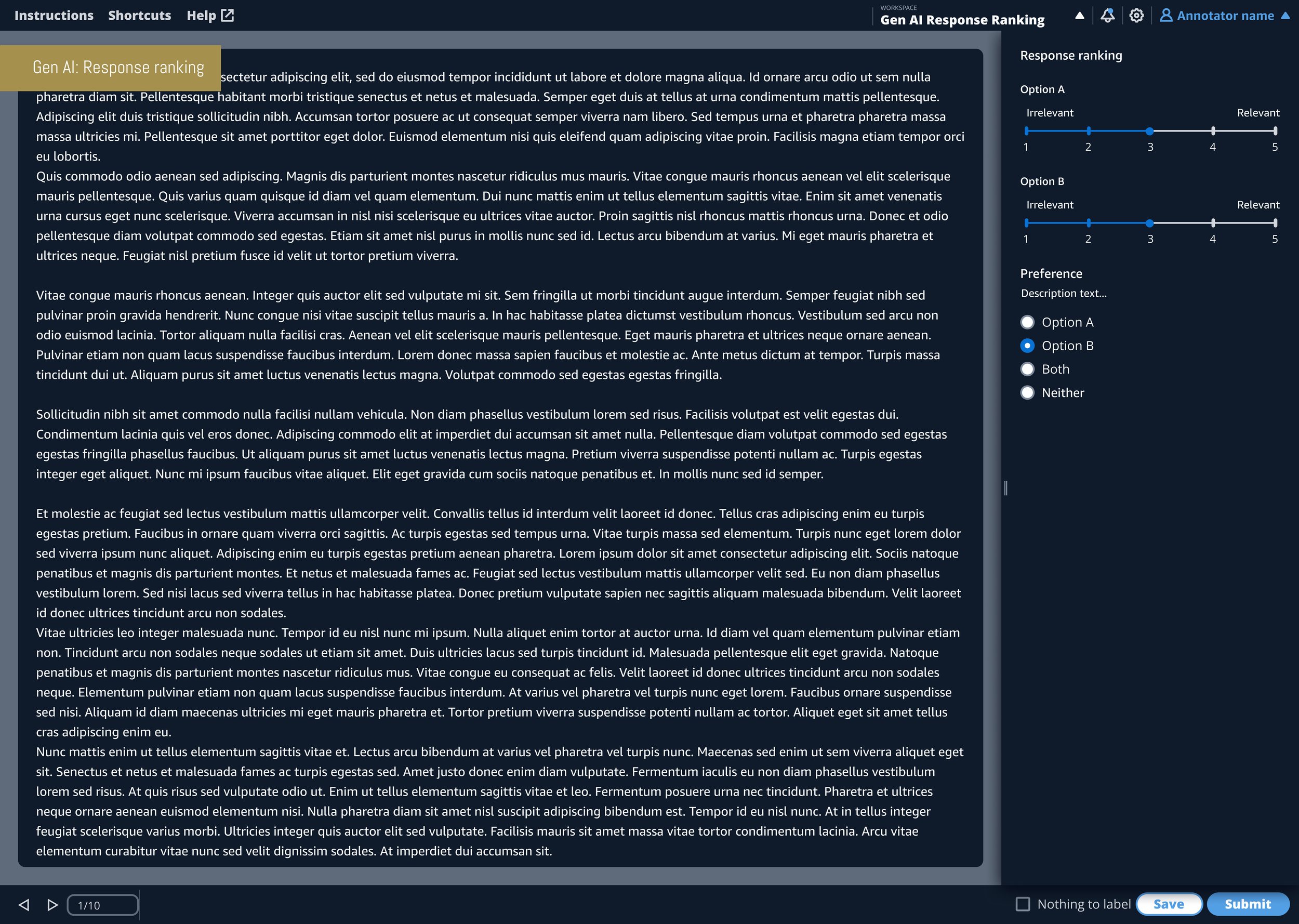
Response ranking
Text generation
On the right, I highlight the Annotator experience screenshots for each use case. As you can see, the products work under a system and pattern, only deviating when there is a strong argument to do so. For example, text generation has no data and therefore leverages the full width of the viewport rather than the right hand side bar.
I would test using these materials (mock ups and prototypes) to test both internally and externally with customers to collect feedback and iterate the designs as necessary.




Test and iterate: End-to-end flows
Below is the end-to-end workflow and high fidelity designs for the Job creator, Annotator and Reviewer for a Text summarization task.



Implement
The following are the net new assets that the team would contribute to AWS’s design system (Cloudscape):



Forward Looking Vision
Below are mock ups of the annotation tool redesign for LIDAR, Video, Image and Text use cases to stretch test the proposed solution.
LIDAR


VIDEO: OBJECT DETECTION AND TRACKING


IMAGE: BOUNDING BOX


IMAGE: CLASSIFICATION


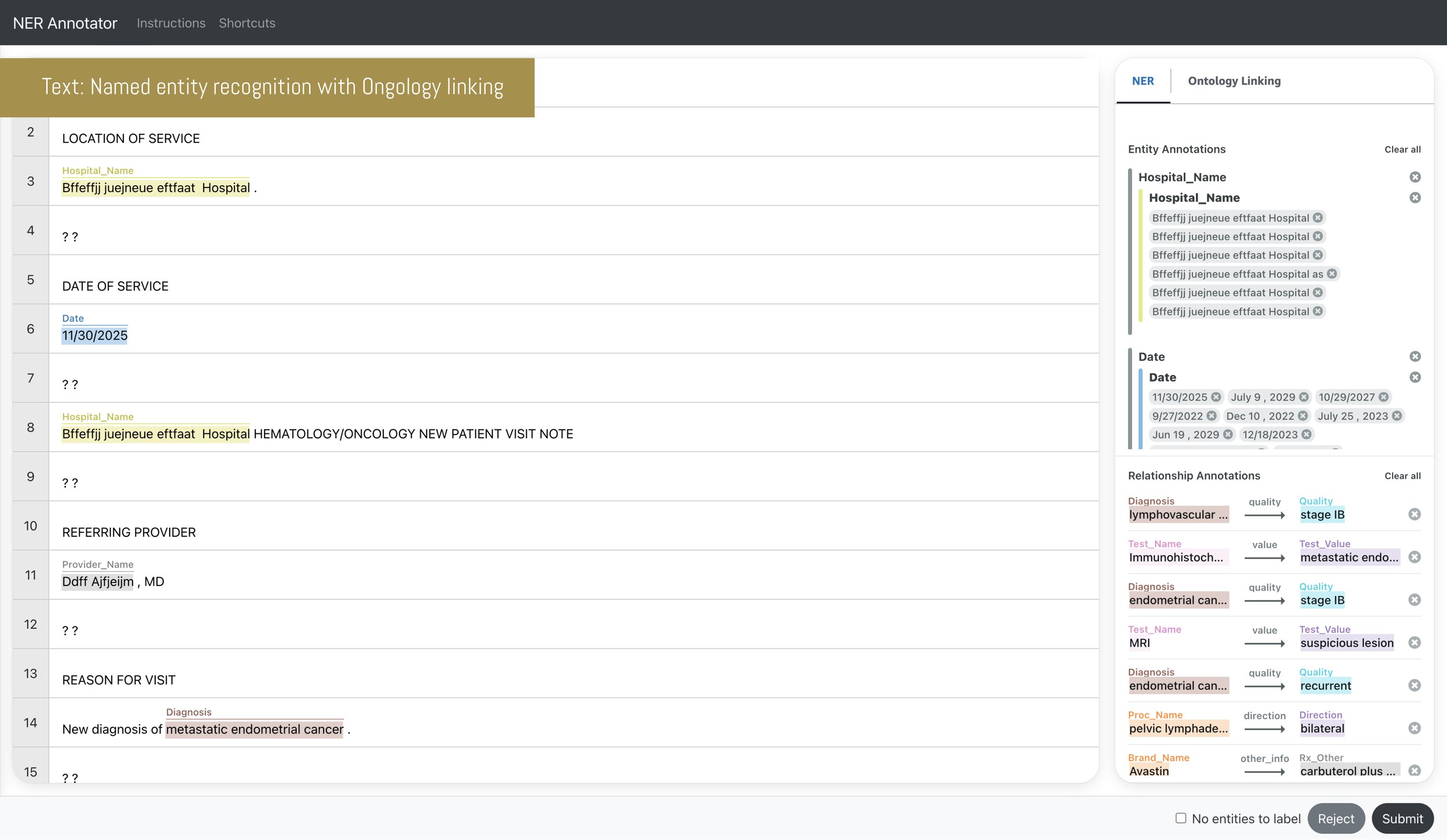
TEXT: NAMED ENTITY RECOGNITION WITH ONTOLOGY LINKING

